NavOL: Navigation Policy with
Online Imitation Learning
ICML 2026
Abstract
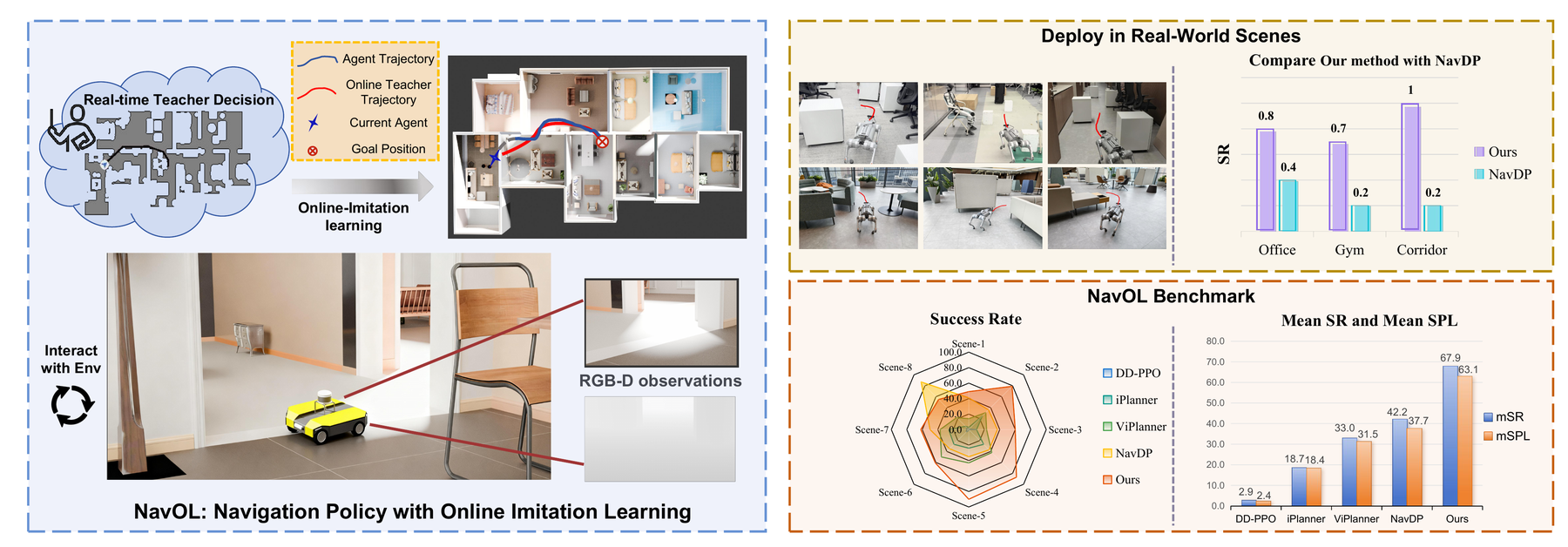
Learning robust navigation policies remains a core challenge in robotics. Offline imitation learning suffers from distribution shift and compounding errors at rollout, while reinforcement learning requires careful reward engineering and learns inefficiently. We propose NavOL, an online imitation learning paradigm that interacts with a simulator and updates itself using expert demonstrations gathered online.
Built upon a pretrained navigation diffusion policy that maps local RGB-D observations to future waypoints, NavOL trains in a rollout–update loop: during rollout, the policy acts in the simulator and queries a global planner with privileged access to the scene for the optimal path segment as ground-truth trajectory labels; during update, the policy is trained on the online-collected observation–trajectory pairs. This online imitation loop removes the need for reward design, improves learning efficiency, and mitigates distribution shift by training on the policy’s own explored rollouts.
Built on IsaacLab with fast, high-fidelity parallel rendering and domain randomization of camera pose and start-goal pairs, our system scales across 50 scenes on 8 RTX 4090 GPUs, collecting over 2,000 new trajectories per hour, each averaging more than 400 steps. We also introduce an indoor visual navigation benchmark with predefined start and goal positions for zero-shot generalization. Extensive evaluations on the NavDP benchmark and our proposed benchmark, as well as carefully designed real-world experiments, demonstrate consistent performance gains of NavOL in online imitation learning.
Method
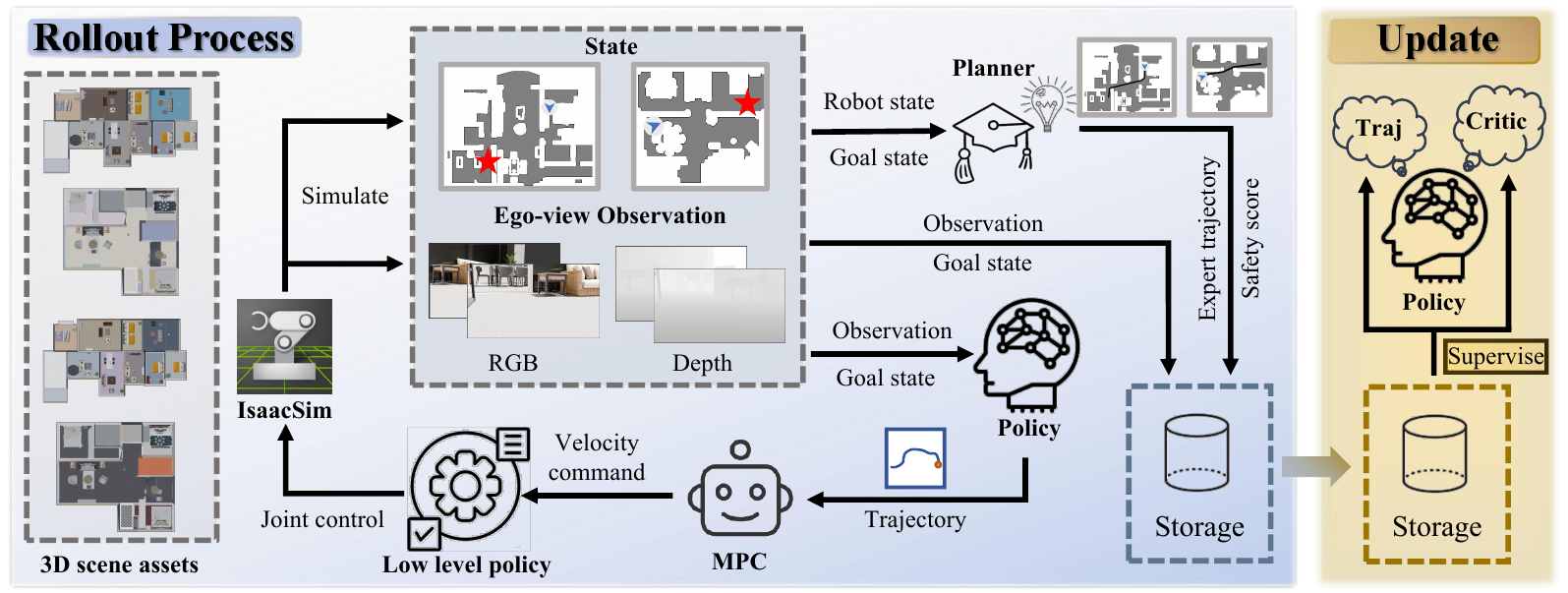
The NavOL rollout–update loop. The policy is initialized from a pretrained navigation diffusion model (NavDP) that maps RGB-D observations and a goal embedding to future waypoint trajectories. At each simulator step, a privileged global planner computes the optimal path segment from the agent’s current pose to the goal, serving as a per-step trajectory label. Rollout data are aggregated into an online buffer and used to update the diffusion policy with the standard DDPM denoising objective. The loop trains on the policy’s own visited state distribution, fundamentally eliminating compounding errors in offline imitation learning.
A New Indoor Navigation Benchmark

We curate a visual indoor navigation benchmark on top of the 3D-Front dataset with predefined start and goal positions, enabling reproducible zero-shot evaluation across image-goal, point-goal, and no-goal settings. The benchmark is designed to stress test long-horizon navigation under partial observation and cluttered layouts.
Qualitative Results

Compared to NavDP and DAgger-Diffusion baselines, NavOL produces noticeably smoother and more obstacle-aware trajectories in cluttered indoor scenes — a direct consequence of training on the policy’s own visited state distribution rather than pre-recorded expert demonstrations.
More Visualizations

In-domain trajectories on 3D-Front scenes.

Real-world deployment on a wheeled robot.
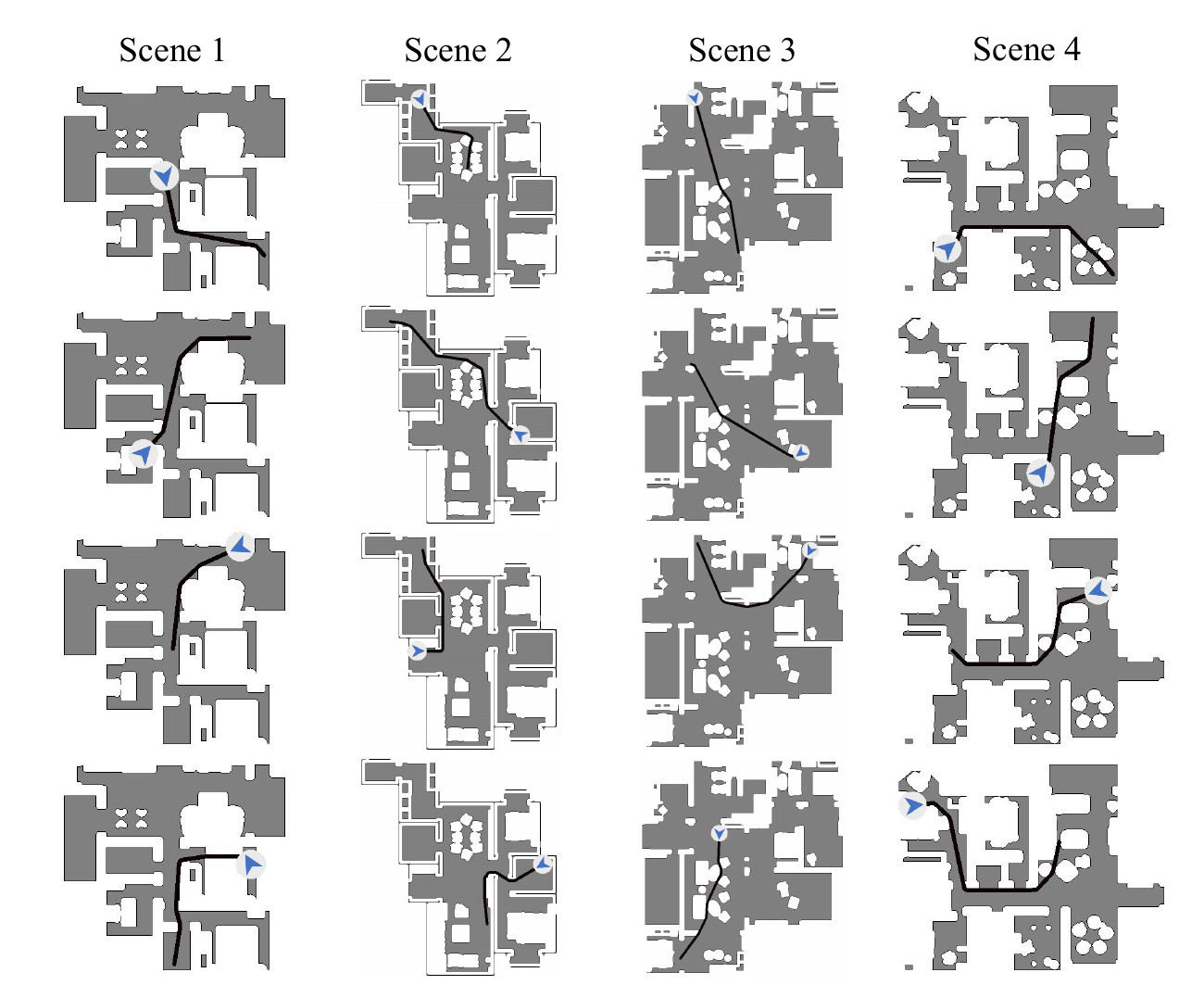
Comparison of planned vs. executed trajectories.

Real-world quantitative results across three scenes.
Real-world Demonstrations
We deploy NavOL zero-shot on a wheeled robot in three real-world indoor scenes, with no real-world fine-tuning. The policy generalizes from purely simulated training to cluttered apartments, an office, and a corridor.
Scene 1 — trial 1
Scene 1 — trial 2
Scene 1 — trial 3
Scene 2 — trial 1
Scene 2 — trial 2
Scene 2 — trial 3
Scene 3 — trial 1
Scene 3 — trial 2
Scene 3 — trial 3
Real-world Captures




Wheeled robot used in our real-world experiments. RGB-D streamed from an onboard depth camera.
BibTeX
@inproceedings{wei2026navol,
title = {{NavOL}: Navigation Policy with Online Imitation Learning},
author = {Wei, Xiaofei and Gu, Chun and Zhang, Li},
booktitle = {Proceedings of the International Conference on Machine Learning (ICML)},
year = {2026}
}